
Global contributions to open-source software (OSS) add tremendous value: for years, they have forged connections between developers around the world, enabled dispersed and specialized talent to build better software for users, and collectively helped ensure that OSS remains available, updated, and relevant for users everywhere. Having more eyeballs on code can bolster the software’s security in some cases, too.
Simultaneously, there are certainly risks that anyone contributing to OSS—including individuals in foreign adversary countries or operating at the behest of those governments—could deliberately contribute vulnerable code to a codebase. Inserting vulnerable code into OSS used by the U.S. government, the American defense base, critical technology companies, and others of interest to foreign adversaries could enable those foreign adversaries to conduct espionage, disrupt and degrade systems, and infiltrate supply chains in unexpected ways.
For example, in early 2024, a programmer “Jia Tan” managed to nearly backdoor the Linux distribution Debian via “XZ utils,” a compression library used in most Linux and Unix-based operating systems. The individual or entity calling themselves Jia Tan managed this by two means: offering much-needed development assistance to the at-the-time socially vulnerable maintainer of XZ utils, who had been managing it without pay for years; and using online profiles to harass the maintainer about the code falling behind. The nominal offer and the harassment at a vulnerable time convinced the maintainer to make Jia Tan a co-maintainer. Jia Tan was therefore able to sneak malicious code into a testing library. Thankfully, another volunteer’s careful eye caught the backdoor soon before it would have been pushed to Debian users. It is unknown whether “Jia Tan” was a government or working for one, but their tactics combined with manipulation of commit data (more on that below) suggest a potential nation-state actor.
Nation-state efforts to undermine OSS security are a problem. But even focusing on a U.S. foreign adversary is not enough to accurately and reliably identify threatening contributions to OSS. Like finding needles in haystacks, the challenge for analysts and policymakers lies in sifting through the many innocuous or beneficial contributions that come from individuals and entities in a country like China—to all kinds of projects and codebases—to identify the subset of contributions that may pose a national security threat. Conversely, imprecise threat identification (e.g., treating all OSS code from China as a threat) can waste resources, turn complex risks into a “risk or no risk” binary, inject harmful “us-versus-them” attitudes into projects that otherwise thrive on the diversity of their maintaining communities, and pull focus away from the areas that really matter. These are counterproductive outcomes.
Large-scale data ingestion and artificial intelligence (AI) analysis capabilities have been a singular tool for researchers working on this problem, especially over the past year. Better understanding the state-of-the-art—and pushing threat analysis and mitigation beyond reductive views of country contributions—will help policymakers and analysts build better defenses against nation-state threats to OSS.
The Power of Analyzing—and Manipulating—Metadata
When programmers contribute to software projects, versioning software platforms (e.g., GitHub, BitBucket, GitLab, etc.) throw in a treat for open-source analysts to find upon inspection: metadata. Almost always, this metadata contains time zone information. Time zone metadata can occasionally help differentiate, at the country level, where in the world a git user is committing from. This is because git time zones are listed in Coordinated Universal Time (UTC), the standard for time zones around the world, which breaks the world’s time zones into 24 blocks from the westernmost (UTC-12:00) to the easternmost (UTC+14:00).
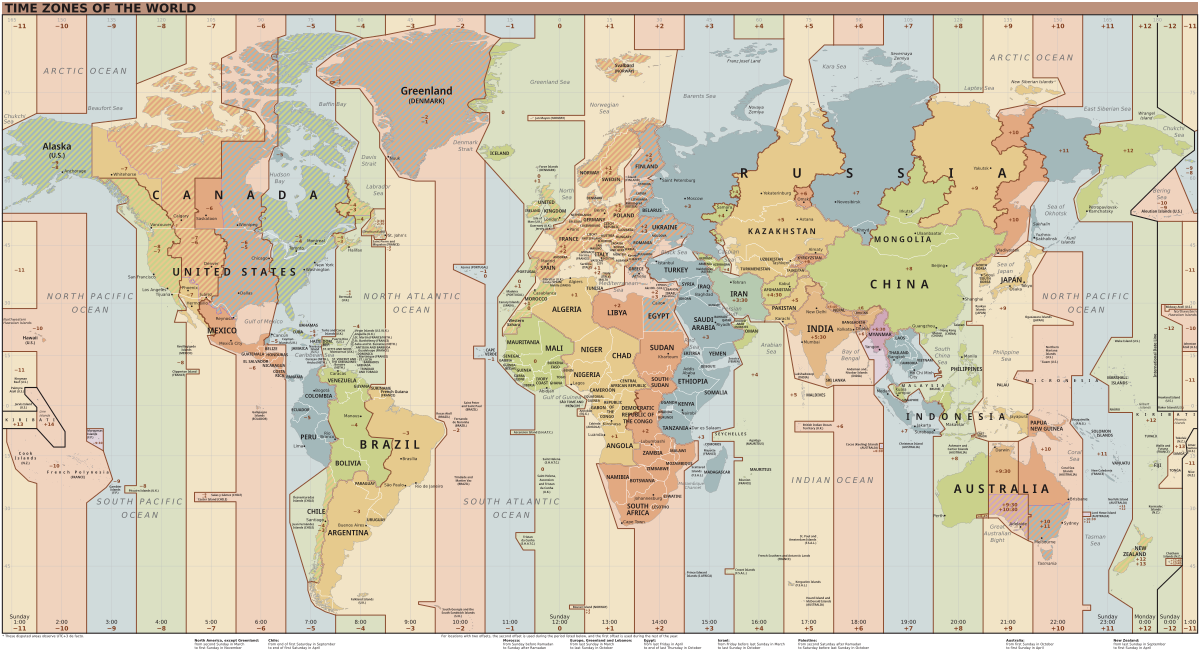
For example, any git commit with timezone UTC+9:30 can be confidently attributed to Australia—either from the states of Northern Territory or South Australia. This is because no other inhabited location on the planet has a timezone of UTC+9:30 at any time of year. To further break down this analysis, South Australia’s standard time zone is UTC+9:30, while its daylight saving time zone is UTC+10:30. Thus, if a user consistently commits from the first Sunday of October at 02:00 to the first Sunday of April at 03:00 from UTC+10:30, and commits the rest of the year from UTC+9:30, it is an indicator that this git user may spend a lot of time programming from South Australia in particular.
While some time zone data may not be immediately significant on its own—e.g., it’s unsurprising that people in California regularly contribute code to US companies—time zone data can also be used to identify anomalous behavior.
Jian Tan, for instance, manipulated metadata and used aliases to avoid identification. This included portraying themselves as having a time zone in China when their actual time zone, upon closer inspection, looks to have lined up with Eastern Europe and Israel, among others. Scrutinizing the timestamps and time zones for each commit in their git history shows that the time zone changes they presented were inconsistent to the point of physical impossibility (barring future teleportation advances, of course):
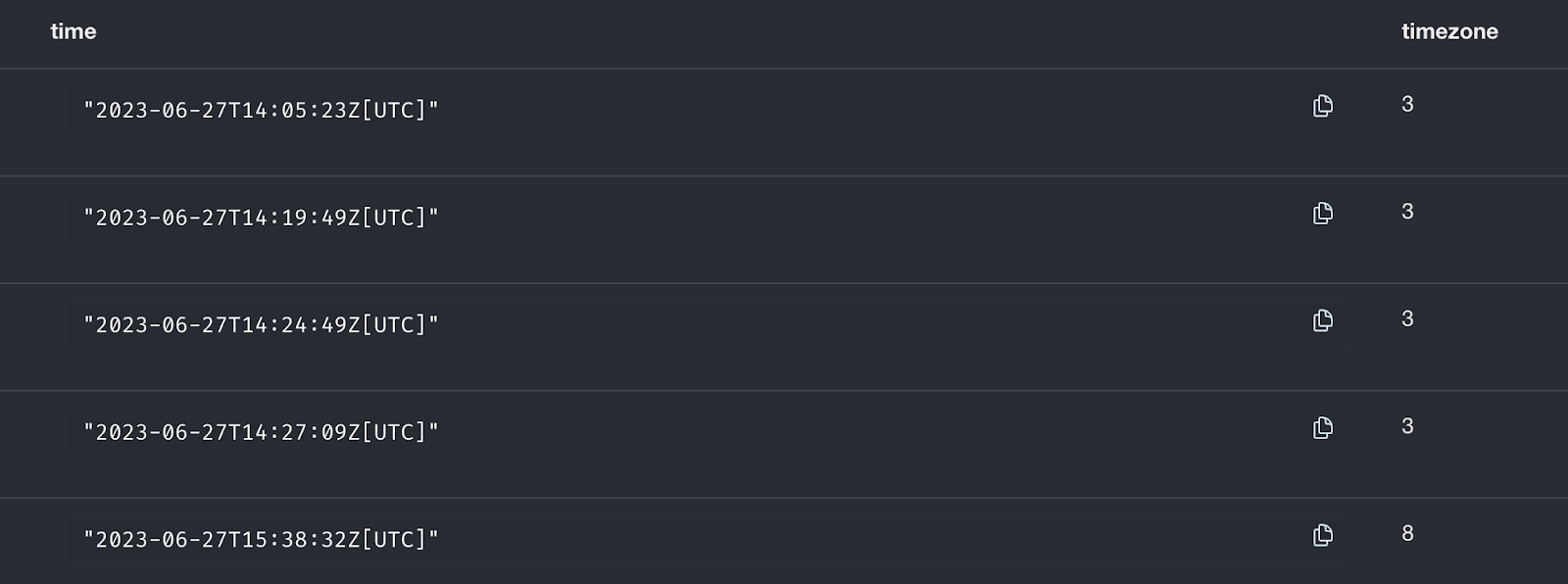
The fourth of these commits was marked as coming from UTC+03:00, which would be somewhere on the eastern edge of Europe. The fifth of these commits, made one hour and 11 minutes later, was marked as coming from UTC+08:00, which would be somewhere on the most western point in China. It is impossible to physically travel between the eastern edge of Europe and the westernmost point in China in one hour and 11 minutes, indicating inauthentic behavior—that is, manual modifications of time zones to make the code contributor appear somewhere they are not. This works because git time zone metadata is system time-specific, not IP address-specific. For example, if you are physically based in Los Angeles (UTC-07:00) and using a VPN that assigns you an IP address in Japan (UTC+09:00), your system time would still show Los Angeles time (UTC-07:00)—and a standard git commit from your computer would therefore show the local time zone (UTC-07:00) rather than the time zone of the VPN-assigned IP address’ location (i.e., Japan, or UTC+09:00).
These kinds of discrepancies, visibly detected when looking through a committer’s time zones, are usually an indication of time zone modifications done sloppily. Because the technologists did not lie to their computers consistently enough, they revealed that their purported and actual locations are likely different.
At the same time, a future Jia Tan could potentially manipulate time zones more effectively; someone with a dedicated computer for maintaining code under a single alias, where they consistently modify metadata the same way each time they push code, might be harder to detect. It is also possible to automatically and consistently manipulate git metadata across entire repositories over time. To continue the previous example, a person in Los Angeles trying to appear as though they are operating out of Japan would have six environment variables they might be interested in modifying: git_author_date, git_committer_date, git_author_email, git_committer_email, git_author_name, and git_committer_name. Git hooks, filters, system-wide environment variable injection, and configuration enforcement can all directly modify this information as the user requires. Git commands can be run automatically alongside other basic repository management tasks within the CI/CD step, as well as during custom git transport and database manipulation. More research and development is needed to detect metadata manipulation on all these fronts and distill those findings down to actionable intelligence.
Searching for buggy code itself is another waypoint in finding bad actors in repositories; after all, the most undetectable exploits are of extant vulnerabilities, rather than injected ones. Jia Tan was originally caught because a keen-eyed developer noticed some odd behavior during a build. However, they were ruled guilty by the malicious code they injected into the testing infrastructure. If such a valuable vulnerability existed before Jia Tan arrived on the scene (so they didn’t have to inject it), the slight difference in that fateful build wouldn’t have been anomalous, and there would be some unknowable threat actor peering through our terminals at us and exfiltrating all sorts of information.
It follows that it is in everyone’s best interest to find vulnerabilities in code as fast as possible, especially in open source codebases. Nobody wants all those eyeballs looking at exploitable bugs for obvious reasons. Luckily, the research here is hot off the press and evolving every minute: easily measurable metrics for human behavioral risk like context switching, project fragmentation, interactive churn, and delta maintainability can be used to point analysts in the direction of likely vulnerabilities, and hopefully help prevent them. Additionally, there are a pile of open source linters, bots, and testers that can do cursory static analysis on code before it’s pushed out into the world. In sum: there is no shortage of ways to protect open source projects from their own vulnerabilities. Adoption of these methods and tools, if not an understanding of why these metrics are important to monitor in keystone systems, must be more widespread if open source software is to remain secure enough to use in the coming decade.
Zooming Back Out
Resource-wise, treating every non-US code contribution as a national security threat is infeasible, even with technologies enabling large-scale data ingestion and analysis. Government employees and contractors have finite time, budget, and numbers of personnel; they cannot focus on everything, everywhere, at all times and treat every piece of code as a threat only because it originates from a certain country. Open-source components are also plugged into all kinds of commercial systems—by one survey of 1,000-plus commercial codebases, in more than 96% of them—making a total rip-and-replace approach infeasible, too (due to both volume of implicated systems and the likelihood of a rip breaking systems). The government is not exempt from this dependence. Part of the premise of DARPA’s SocialCyber project is that the Defense Department has critical dependencies on OSS across operating systems, virtualization systems, hypervisors, tool chains for software development, and other parts of its supply chain.
Conversely, a more tailored approach to OSS and national security would aim to identify contributions that pose the greatest national security risks—so the government can focus its mitigation efforts on those areas. For example, if an OSS codebase has many contributors in Russia, using automated and human analysis to identify which are bug fixes and which are quiet insertions of vulnerabilities could help a government agency decide which dependencies are safe and which are a threat. This automated and human analysis of course can and should draw on other information and data available as well.
At the end of the day, OSS—critical for the maintenance of public infrastructure, keystone in every commercial software available, underpinning the internet—is a global project, maintained and contributed to by whomever will rise to the challenge. Huge benefits from a collaborative, global OSS ecosystem and plentiful geopolitical, adversarial, and national security considerations exist at once. Better navigating threat analysis, including for the US government, will help achieve the right balances into the future.