Cannoli
Cannoli is a high-performance tracing engine for qemu-user. It can record a trace of both PCs executed as well as memory operations. It consists of a small patch to QEMU to expose locations to inject some code directly into the JIT, a shared library which is loaded into QEMU to decide what and how to instrument, and a final library which consumes the stream produced by QEMU in another process, where analysis can be done on the trace.
Cannoli is designed to record this information with minimum interference of QEMU's execution. In practice, this means that QEMU needs to produce a stream of events, and hand them off (very quickly) to another process to handle more complex analysis of them. Doing the analysis during execution of the QEMU JIT itself would dramatically slow down execution.
Cannoli can handle billions of target instructions per second, can handle multi-threaded qemu-user applications, and allows multiple threads to consume the data from a single QEMU thread to parallelize processing of traces.
Check out the code here!
https://github.com/MarginResearch/cannoli
Introduction
When working with program analysis, we often find ourselves scratching our heads at the best way to get information about program execution. There's the standard way of just... attaching a debugger, there's using dynamic instrumentation like PIN, using some fancy features like Intel PT, or just throwing it in an emulator. Unfortunately, many of these solutions have some pretty expensive performance costs, or in the case of something like Intel PT, only work on x86.
One of the big problems of tracing is simply performance. Many simple solutions like using Unicorn for emulation can lead to getting only a million or so emulated instructions per second. This may sound like a lot, but a modern x86 processor will often do 2 instructions per cycle. If you're running on a 4 GHz processor, something that takes 1 second to run or start, often is executing well into the 5-10 billion instructions territory. Simply put, tracing something like this at even 10 million instructions per second is prohibitively slow for any development or research cycle.
Just trying to get a full log of addresses of instructions executed (what we'll call PC's), often is a challenge enough, let alone when you want to log all memory accesses as well. It turns out, this is a relatively hard problem, and we've taken a swing at it.
That leads us to Cannoli! A high-performance tracing engine for qemu-user. Designed explicitly to minimize overhead of recording full traces of both code flow (all PCs executed), as well as memory operations (address, size, value, and information about if it's a read or a write).
Cannoli is capable of performing full-tracing of QEMU with about a 20-80% slowdown over base QEMU execution. This means that it's possible to get about 1 billion target instructions/second of traces. This varies a lot by your CPU clock rate, system noise, etc. We'll get into the details of performance later on as there is a lot of nuance. Ultimately something around 500M-1B target instructions/second is likely achievable with full tracing of both PCs and memory operations, which is pretty good!
Cannoli has been super carefully designed and can stream over 20 GiB/second of data from a single QEMU thread to the multi-threaded trace analysis process. For those more familiar with networking, Cannoli is generating and IPCing about 180Gbps of data from a single producer thread!
Demo
User Experience
To start off, we should cover what you should expect as an end-user.
QEMU Patches
As a user you will have to apply a small patch set to QEMU, consisting of about 200 lines of additions. These are all gated with #ifdef CANNOLI, such that if CANNOLI is not defined, QEMU builds identically to having none of the patches in the first place.
The patches aren't too relevant to the user, other than understanding that they add a -cannoli flag to QEMU which expects a path to a shared library. This shared library is loaded into QEMU and is invoked at various points of the JIT.
To apply the patches, simply run something like:
git am qemu_patches.patchCannoli Server
The shared library which is loaded into QEMU is called the Cannoli server. This library exposes two basic callbacks in cannoli_server/src/lib.rs.
/// Called before an instruction is lifted in QEMU. If this function returns
/// `true`, then the instrumentation is added and this PC will generate logs
/// in the traces.
///
/// This may be called from multiple threads
fn hook_inst(_pc: u64) -> bool {
true
}
/// Called when a memory access is being lifted in QEMU. Returning `true` will
/// cause the memory access to events in the trace buffer.
///
/// This may be called from multiple threads
fn hook_mem(_pc: u64, _write: bool, _size: usize) -> bool {
true
}These hooks provide an opportunity for a user to decide whether or not a given instruction or memory access should be hooked. Returning true (the default) results in instrumenting the instruction. Returning false means that no instrumentation is added to the JIT, and thus, QEMU runs with full speed emulation.
This API is invoked when QEMU lifts target instructions. Lifting in this case, is the core operation of an emulator, where it disassembles a target instruction, and transforms it into an IL or JITs it to another architecture for execution. Since QEMU caches instructions it has already lifted, these functions are called "rarely" (with respect to how often the instructions themselves execute), and thus this is the location where you should put in your smart logic to filter what you hook.
If you hook a select few instructions, the performance overhead of this tool is effectively zero. Cannoli is designed to provide very low overhead for full tracing, however if you don't need full tracing you should filter at this stage. This prevents the JIT from being instrumented in the first place, and provides a filtering mechanism for an end-user.
Cannoli Client
Cannoli then has a client component. The client's goal is to process the massive stream of data being produced by QEMU. Further, the API for Cannoli has been designed with threading in mind, such that a single thread can be running inside qemu-user, and complex analysis of that stream can be done by threading the analysis while getting maximum single-core performance in QEMU itself.
Cannoli exposes a standard Rust trait-style interface, where you implement Cannoli on your structure. As an implementer of this trait, you must implement init. This is where you create a structure for both a single-threaded mutable context, Self, as well as a multi-threaded shared immutable context Self::Context.
You then optionally can implement the following callbacks:
fn exec(_ctxt: &Self::Context, _pc: u64) -> Option<Self::Trace>;
fn read(_ctxt: &Self::Context, _pc: u64, _addr: u64, _val: u64)
-> Option<Self::Trace>;
fn write(_ctxt: &Self::Context, _pc: u64, _addr: u64, _val: u64);
-> Option<Self::Trace>;
fn trace(&mut self, _ctxt: &Self::Context, _trace: &[Self::Trace])These callbacks are relatively self-explanatory, with the exception of the threading aspects. The three main execution callbacks exec, read, and write can be called from multiple threads in parallel. Thus, these are not called sequentially. This is where stateless processing should be done. These also only have immutable access to the Self::Context, as they run in parallel. This is the correct location to do any processing which does not need to know the ordering/sequence of instructions or memory accesses. For example, applying symbols where you convert from a pc into a symbol + address should be done here, such that you can symbolize the trace in parallel.
All of the main callbacks, exec, read, and write, return an Option<Self::Trace> type. This is a user-defined type which should be thought of as a form of a filter_map. If you return None, the event is not placed into the trace, if you return Some(your_value) then your_value will be placed sequentially into a trace buffer.
This trace is then exposed back to the user fully in-order via the trace callback. The trace callback is called from various threads (eg. you might run in a different TID), however, is it ensured to always be called sequentially and in-order with respect to execution. Due to this, you get mutable access to self, as well as a reference to the shared Self::Context.
I know this is a weird API, but it effectively allows parallelism of processing of the trace until you absolutely need it to be sequential. I hope it's not too confusing for end users, but processing 1 billion instructions/second of data kind of requires threading on the consumer side, otherwise you bottleneck QEMU!
Performance
Note: Unless otherwise noted, performance numbers here are on my Intel(R) Xeon(R) Silver 4310 CPU @ 2.10GHz. Hyperthreading enabled, turbo enabled, 128 GiB RAM @ 2667 MHz w/ 8 memory channels
At a high level, the entire design revolved around a producer of massive amounts of data (a QEMU thread running in the JIT). For Cannoli we are optimizing specifically for QEMU single-threaded throughput of QEMU such that we can get introspection into long-running or big processes, like a web browser.
This is different from scaling, where you don't really care about the performance of an individual thread, rather the system as a whole. In our case, we want to support streaming billions of instructions per second from a single QEMU thread, while doing relatively complex analysis of that data with threaded consumers.
Basic Benchmark
Included you’ll find a benchmark in examples/benchmark which runs a small mipsel binary that just executes a bunch of nops in a loop. This is meant to benchmark the performance of the PC tracing.
To use this benchmark, spin up the benchmark client:
cd examples/benchmark && cargo run --releaseAnd then run the benchmark with a cannoli'd QEMU!
/home/pleb/qemu/build/qemu-mipsel -cannoli ~/cannoli/target/release/libcannoli_server.so ./benchmarkIn my case, on my 2.1 GHz CPU (read: very low clock rate compared to most desktops), I get the following (in my case I used benchmark_graph ).
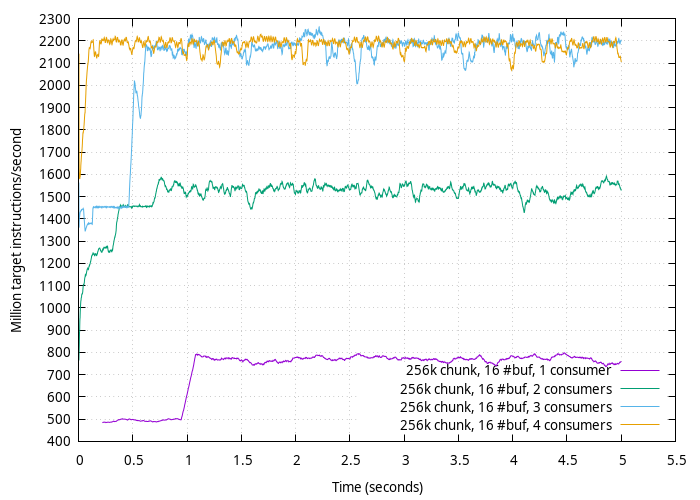
About 2.2 billion instructions per second of tracing on a single QEMU thread!
Mempipe
Getting this level of tracing with a low-performance overhead required some pretty interesting engineering. At the core of Cannoli is a library called mempipe. At a high-level, this is an extremely low-latency shared-memory IPC mechanism.
On top of this, the design for the JIT hooks has been to decrease overhead as much as possible, with careful attention to details like branch prediction, code size (for reducing icache pollution), and being aware of the target architectures bitness to reduce the amount of data produced when running 32-bit targets.
In fact, you'll find that pretty much all of the APIs, but the top-level Cannoli trait, leverage Rust macros to define two copies of the same code, one for 32-bit targets, and one for 64-bit targets. This slightly increases the code complexity, but when we're saturating memory bandwidth, we want to special case that 32-bit targets have effectively 1/2 of the data being produced due to
smaller pointer sizes.
The core mempipe IPC mechanism allows for transferring buffers between processes that fit inside of L1 cache. Since these buffers are so small, the frequency of IPC packets is extremely high. For networking people, this is effectively a high requirement for packets-per-second. In my case, I can do about 10 million transfers per second of a 1-byte payload. This is with one producer thread and one consumer thread. This is effectively saturating what the Intel silicon can do for cache-coherency traffic.
Cache Coherency
If you're not familiar with cache coherency, it's what your processor does to make sure memory is observed to be the same value on all processors, even if it's stored in multiple caches.
The simple model is the MESI model. This defines the state each cache line can be in. MESI stands for.
- Modified - Data stored in a cache line is "dirty", and is the only accurate copy of memory
- Exclusive - Data stored in a cache line is clean (same data in the cache line as well as memory), and this is the only copy of the memory in a cache line on the system
- Shared - Data stored in a cache line is clean, and there are multiple different caches on the system which are storing this same information
- Invalid - Doesn't mean anything to us at the software level, it just means the cache line is unused (and thus free for using)
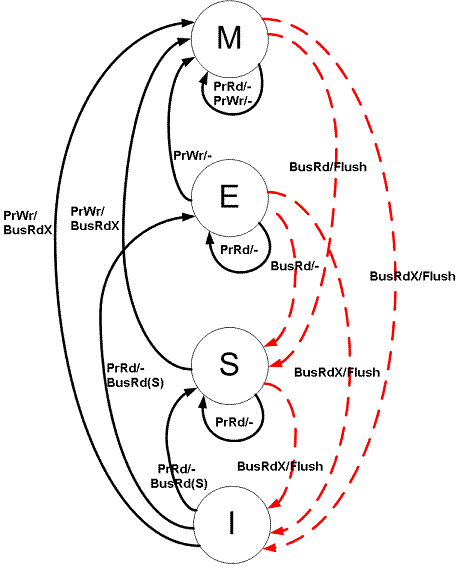
Now, modern processors use a slightly more complicated cache coherency model, but we won't go into that here. At its core, it's the same.
What's important to note is that any time cores have to sync their caches, they have to hit L2 cache (some exceptions, won't cover that here), and sometimes even memory.
If you think about it like the Rust memory-safety model, modified is a dirty &mut self, exclusive is an unchanged &mut self, and shared is a &self. The costs to switch between these cache line states is not cheap.
More specifically, going to the modified state is an expensive transition. Think about it, to get exclusive access to memory you effectively have to do a lock to get control. In a hardware point of view, you have to tell every other core to invalidate its cache for a given line, and you can't take ownership until the other cores have done as such. This is effectively like doing a Mutex::lock().
Going from exclusive to modified is cheap, however. It's the whole point of the exclusive MESI state. It allows the processor to know it doesn't have to notify other cores when transitioning to modified, as it's already known to be the only copy of the memory.
Why are we talking about this? Well, when doing IPC, cache coherency matters a lot. It's critical that in our hot loops we are not causing cache coherency traffic. At a high level, this means that we need to be able to hot poll all our data structures by reading only. This allows multiple consumer threads to be polling the mailboxes (eg. all of the consumers are polling a cache line that is in the shared state). We only want to pay the cache-coherency cost of writing to memory when the producer has produced a full buffer. The act of the producer flushing a buffer will cause all consumer cores to have their caches invalidated, and they'll have to fetch the memory through L2 on the subsequent access. This fetch has to drop the producer's cache state from modified to shared as well.
Thus, we've designed the mempipe library to poll a set of mailboxes which is guaranteed to be on a different cache line from the data being transferred. If we had the transfer buffer on the same cache line as the mailboxes then there would be major cache thrashing!
Internals

Mempipe
Mempipe is the super-fast IPC mechanism that really enables Cannoli to work in the first place. It provides a low-latency API for transferring buffers from one process to another via shm*() APIs on Linux. Specifically, it is a polling-based IPC mechanism, meaning the consumer is hot-polling a mailbox until new data arrives.
You can find all the code in mempipe/src/lib.rs. At its core it exposes two structures, a SendPipe and a RecvPipe.
Const Generics
Both SendPipe and RecvPipe use two constant generics. These are the CHUNK_SIZE and NUM_BUFFERS generics. CHUNK_SIZE defines the size of each buffer in bytes. The smaller this chunk size, the more transfers have to happen, but the more data you fit into caches. This is effectively the size of the buffer which will be filled up with data, and flushed to the consumer when it's full.
The NUM_BUFFERS generic specifies the number of buffers in the memory pipe. Effectively, this is what enables non-blocking streaming of data from QEMU. A consumer can be processing a buffer while QEMU is producing data to another buffer. Setting this to greater than one is recommended, otherwise QEMU will block while the buffer is processed... but don't set it too high; that just increases the amount of memory that might be used for streaming, causing more cache thrashing.
Both of these generics are tunables and dramatically affect performance. Personally, I've found that setting the CHUNK_SIZE to 1/2 that of L1 cache (16 KiB on most x86 systems), and NUM_BUFFERS to 4 seems to be a good metric.
Pipe Creation
Creating a SendPipe is simple. You call SendPipe::create() and it returns back a SendPipe. Internally, it generates a random 64-bit number which is used as the pipe identifier. It then creates a shared memory file with this pipe ID as the filename, sets the length of the shared memory, and maps it in as read-writable. We also place a small header into shared memory so we can make sure when we connect to the pipe it matches the parameters we expect.
Pipe Opening
Creating a RecvPipe is also simple, just call RecvPipe::open() with the UID assigned to the SendPipe (obtainable from SendPipe::uid()). This will open the shared memory with the provided UID, Then, make sure the constant generics of the RecvPipe match those of the SendPipe (included in the metadata of the shared memory), and finally it will map the memory and return back the pipe.
Data Production
To produce data from the SendPipe, you call SendPipe::alloc_buffer. This gives the user a write-only ChunkWriter which can be written with ChunkWriter::send. Calling alloc_buffer will block in a hot-loop until a buffer is available. It is important that a consumer is consuming the data as fast as possible to prevent the sender from stalling too long. With the right tunables, the consumer should always be ahead of the producer, and thus alloc_buffer should effectively return immediately.
When a buffer is obtained via alloc_buffer, it is guaranteed to be owned by the sending process, and thus we can safely write to it mutably. The memory is uninitialized, but that's okay because ChunkWriter only provides write access, and thus reading the uninitialized memory is impossible.
Data Consumption
Okay, as of this writing I'm not super happy with the final design for consuming data. First, you request a ticket from RecvPipe::request_ticket. This effectively lets the pipe know that you are interested in data, and gets you a unique ID of the data you will process. You then call RecvPipe::try_recv which consumes the ticket, and will return back either a new ticket (if data was processed), or the old ticket (if the recv didn't have any data). try_recv is non-blocking. If no data is present, it immediately returns.
The ticket model is a bit strange, but it allows us to round-robin assign consumer threads to buffers. This distributes the load of processing as evenly as possible among the processing threads. It also is important as it determines the sequencing of the data being processed, which is important for our tracing requirements of being well-ordered.
I'd like to find an improvement to this API, but I just haven't bothered yet, largely because it works fine and is super fast.
QEMU Patches
Included with Cannoli are a few patches to QEMU. You'll find these in the repo in the file qemu_patches.patch. These are currently patches for latest QEMU eec398119fc6911d99412c37af06a6bc27871f85 as of this writing), however they are designed to be pretty portable between QEMU versions.
The patches introduce about ~200 lines of code into QEMU.
QEMU Hooks
When the -cannoli command line argument is passed into QEMU, it triggers a dlopen() of the Cannoli shared library. It then gets the address of the Cannoli entry point (called query_version32 or query_version64). The 32 or 64-bit suffix is not referring to the bitness of the shared library itself (everything currently only supports x86_64 as a host/JIT target), however it refers to the bitness of the target being emulated. All the hooks have been designed to work with 32-bit and 64-bit targets differently, as this decreases the size of the data stream, and thus, maximizes performance when a 32-bit target is being emulated.
Calling query_versionX returns a reference to a Cannoli structure which defines various callbacks which QEMU will dispatch to upon certain events.
Register reservation
Since we will be producing data on nearly every single target instruction, we actually want to store a small amount of metadata about the trace buffer and length in registers. Doing this in memory would be quite expensive as it would cause multiple memory accesses to occur for every target instruction.
Thus, we patch the tcg_target_reg_alloc_order to remove the x86_64 registers r12, r13, and r14 from use with the QEMU register scheduler. This prevents QEMU from using them for its JIT, and thus gives us exclusive control of these registers during execution inside the JIT. These registers were picked as they are callee-saved registers based on the SYS-V ABI. This is important as QEMU can call into C functions inside the JIT, and we want to make sure our registers are preserved when these calls occur.
JIT entry and exit
Since we reserve control over a few registers, we need to make sure those registers are correctly set and preserved across QEMU JIT entries and exits. JIT entries and exits are the boundaries where QEMU transitions from running the QEMU C code, to running the generated JIT code, and back to exiting to QEMU again. These entries and exits are defined for each JIT-target-architecture in the tcg_target_qemu_prologue() function. This effectively sets up context, calls into the JIT, and restores context. For someone familiar with OS-development, this is effectively a context switch.
We add some hooks in here that allow us to invoke code in our Rust shared library. Specifically, the jit_entry() and jit_exit() functions. These are called inside the context of the JIT and provide access to the r12, r13, and r14 registers such that they can be saved and restored on every JIT entry and exit.
In our case, the $entry function (cannoli/cannoli_server/src/cannoli_internals.rs) allocates a buffer from mempipe, sets a pointer to it in r12, sets a pointer to the end of it in r13, and returns back. This establishes the state for r12 and r13 through the execution of the JIT.
The $exit function determines the number of bytes produced by the JIT (as indicated by the current pointer in r12, which has advanced), and sends the data over IPC to the consumer!
Loads and stores
For loads and stores we hooked tcg_out_qemu_ld() and tcg_out_qemu_st(). These are x86_64-JIT-target-specific functions and they provide catch-all sinks for memory operations to the guest address space for their respective loads and stores.
Instruction execution
For instruction execution we hook tcg_gen_code(), and specifically, the INDEX_op_insnstart() QEMU TCG instruction which denotes the address of the instruction starting execution.
JIT shellcode injection
Both the memory and instruction hooks do the same thing. They invoke a callback in our Rust code which is passed a QEMU-provided buffer and length. This callback then can fill the QEMU-provided buffer with shellcode which is emit directly into the JIT stream. This provides our Rust library with the ability to inject arbitrary code into the JIT stream. If you're a power-user, you can do really cool things with this, by providing different hooks for different instructions.
Cannoli Server
The Cannoli server (SO loaded into QEMU with hooks) has a few hooks already pre-defined. These are the instruction and memory operation hooks.
The entire flow of Cannoli (in its default configuration) is to allocate an IPC buffer on JIT entry, fill it in during the JIT, flush it if it fills up, and also flush it on JIT exits.
The default instruction and memory hooks do the minimal amount of assembly needed to make sure there's enough space left in the trace buffer, flushing it (by calling back into Rust if it's full, it's okay to call into Rust here as these events happen "rarely", eg. every few thousand target instructions), and finally storing the memory or instruction execution instruction into the trace in a relatively simple format.
The Cannoli server shared object contains two copies of all the hooks and code, such that the same shared object can be used with both 32-bit and 64-bit targets, without recompiling!
I'm not going to go into crazy details of all the hooks here, they're fairly well commented.
TL;DR:
cannoli_insthook\bits:
; r12 - Pointer to trace buffer
; r13 - Pointer to end of trace buffer
; r14 - Scratch
; Allocate room in the buffer
lea r14, [r12 + \width + 1]
; Make sure we didn't run out of buffer space
cmp r14, r13
jbe 2f
; We're out of space! This happens "rarely", only when the buffer is full,
; so we can do much more complex work here. We can also save and restore
; some registers.
;
; We directly call into our Rust to reduce the icache pollution and to get
; some code sharing for the much more complex flushing operation
;
; Flushing gets us a new r12, r13, and r14
mov r13, {REPLACE_WITH_FLUSH}
call r13
2:
.if \bits == 32
; Opcode
mov byte ptr [r12], 0x00
; PC, directly put into memory from an immediate
mov dword ptr [r12 + 1], {REPLACE_WITH_PC}
.elseif \bits == 64
; Opcode
mov byte ptr [r12], 0x80
; Move PC into a register so we can use imm64 encoding
mov r14, {REPLACE_WITH_PC}
mov qword ptr [r12 + 1], r14
.else
.error "Invalid bitness passed to create_insthook"
.endif
; Advance buffer
add r12, \width + 1cannoli_memhook_\access\()_\data\()_\addr\():
; r12 - Pointer to trace buffer
; r13 - Pointer to end of trace buffer
; r14 - For reads, this always holds the address, for writes, it's scratch
; Allocate room in the buffer (we have to preserve r14 here)
lea r12, [r12 + (\width * 2 + \datawidth + 1)]
cmp r12, r13
lea r12, [r12 - (\width * 2 + \datawidth + 1)]
jbe 2f
; We're out of space! This happens "rarely", only when the buffer is full,
; so we can do much more complex work here. We can also save and restore
; some registers.
;
; We directly call into our Rust to reduce the icache pollution and to get
; some code sharing for the much more complex flushing operation
;
; Flushing gets us a new r12, r13, and r14
mov r13, {REPLACE_WITH_FLUSH}
call r13
2:
.ifc \access, read
; Read opcode
mov byte ptr [r12], (((\width / 4) - 1) << 7) | 0x10 | \datawidth
.endif
.ifc \access, write
; Write opcode
mov byte ptr [r12], (((\width / 4) - 1) << 7) | 0x20 | \datawidth
.endif
; Address and data
.if \width == 4
mov dword ptr [r12 + (\width * 0 + 1)], {REPLACE_WITH_PC}
.elseif \width == 8
mov r14, {REPLACE_WITH_PC}
mov [r12 + \width * 0 + 1], r14
.endif
mov [r12 + \width * 1 + 1], \addr
mov [r12 + \width * 2 + 1], \data
; Advance buffer
add r12, \width * 2 + \datawidth + 1These hooks write directly into the buffer provided from mempipe, and it's really that simple! Anything more complex would have hurt performance too much!
Cannoli
Finally, Cannoli itself is the consumer library which revolves around a trait that you implement in Rust.
Since we're working with potentially billions of instructions per second, we've designed all of Cannoli to work with threads. This allows you to do relatively complex consuming and processing of traces on multiple threads, while not affecting the QEMU single-threaded task.
This is pretty straight forward. Cannoli creates the number of threads requested, and spins on those threads waiting for data. With the mempipe ticket system, each thread waits for their turn in line for their data to come in. When the buffer comes up with their ticket number, that thread processes the data from QEMU. This happens in parallel, threads will pick up data when they
are ready and process it.
Since processing in parallel means that the trace is no longer in-order, we allow the user to return their own structure for each event, which is then returned back to them at a later point after it has been sequenced. This allows a user to do threaded processing until the very point where they require ordering (eg. execution flow is being followed rather than just caring about raw PC events).
Conclusion
Transferring data from one process to another as fast as possible is a really hard problem. Minute details about the processor, such as cache coherency, is critical to getting high-throughput, especially when you want to prevent blocking of the producer thread as much as possible.
I hope you've enjoyed this little write up Cannoli, and find some creative uses for the code.
Future
I have some crude hooks that allow for logging of registers when an instruction is hit (eg. to get the register state on malloc() and free()) however that's not quite solidified. Mainly because it requires per-target-architecture hooks in QEMU and requires a consumer to be aware of how many target registers the architecture has. It'd be easy to add in, but kinda hard to do well IMO.
For code coverage I often do self-modifying JITs where the code "patches itself out" once it has been hit once. I'd love to support this as an option, where upon requesting a hook of an instruction, you can also request it to be a one-shot hook. This would allow for cheap hooks that converge to almost zero-cost, for things where you just want to know if it's been hit or not.
There's always room for better performance.